VALL-E
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Paper: https://arxiv.org/abs/2301.02111Abstract. We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis.
official demo page: https://valle-demo.github.io
lifeiteng's implementation: https://github.com/lifeiteng/vall-e
my fork: https://github.com/ceastld/vall-e
This page is for showing reproduced results only, I keep the main parts of the official demo.
Model Configs
| Item | The Paper | LJSpeech Model | LibriTTS Model | AiShell2 Model |
|---|---|---|---|---|
| Transformer | Dim 1024 Heads 16 Layers 12 | Dim 1024 Heads 16 Layers 12 | Dim 1024 Heads 16 Layers 12 | Dim 1024 Heads 16 Layers 12 |
| Dataset | LibriLight 60K hours | LJSpeech 20 hours | LibriTTS 0.56K hours | AiShell2 1K hours |
| Machines | 16 x V100 32GB GPU | 1 x RTX 24GB GPU | 1 x RTX 24GB GPU | 4 x RTX 24GB GPU |
Model Overview
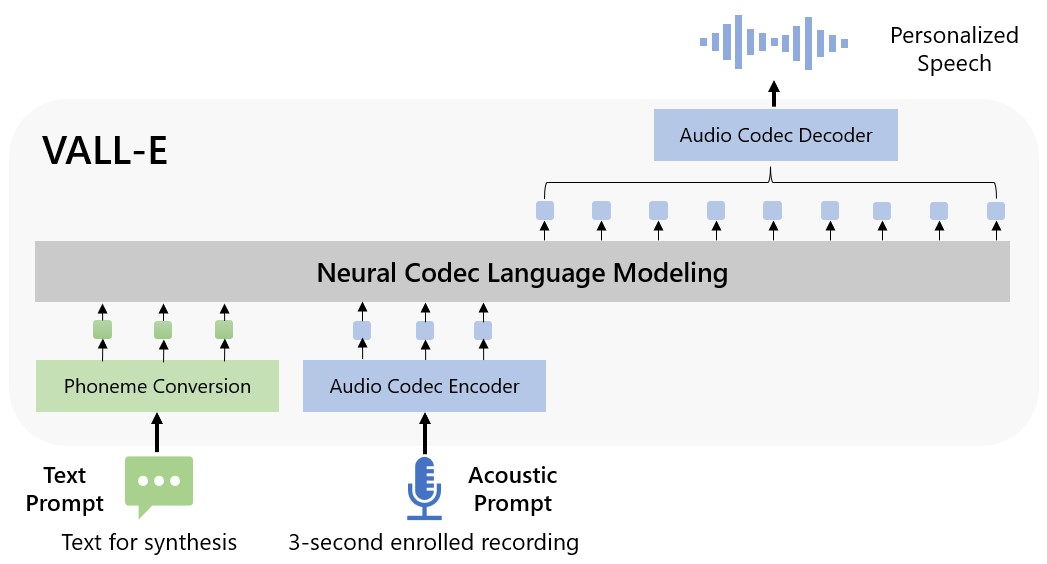
The overview of VALL-E. Unlike the previous pipeline (e.g., phoneme → mel-spectrogram → waveform), the pipeline of VALL-E is phoneme → discrete code → waveform. VALL-E generates the discrete audio codec codes based on phoneme and acoustic code prompts, corresponding to the target content and the speaker's voice. VALL-E directly enables various speech synthesis applications, such as zero-shot TTS, speech editing, and content creation combined with other generative AI models like GPT-3.
Genshin Samples on Train set
| Text Prompt | Speaker Prompt | Text | Ours Genshin Model |
|---|
Genshin Samples on Test set
用原神数据训练的模型在测试上的效果
| Text Prompt | Speaker Prompt | Text | Ours Genshin Model |
|---|
Genshin Model 在测试集以外的数据上效果
用原神数据训练的模型在测试以外的效果
| Text Prompt | Speaker Prompt | Text | Synthesized Speech |
|---|